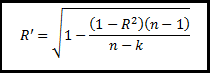In this post, we will discuss about the different rotation
methods available in SPSS, and use each of method.
We will start with the definition of rotation and usefulness
of rotation in factor and principal component analysis.
According to Yaremko, Harari, Harrison, and Lynn, factor
rotation is as follows:
“In factor or principal-components analysis, rotation of the
factor axes (dimensions) identified in the initial extraction of factors, in
order to obtain simple and interpretable factors.”
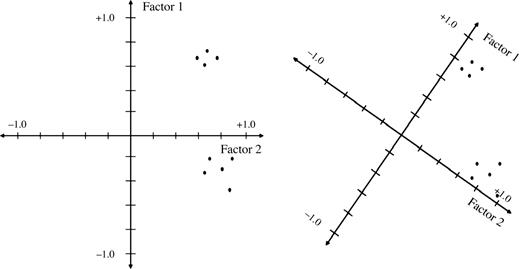
Types of Rotation: There are 2 types of rotations.
1- Orthogonal Rotation: These methods assumes that the factors or components
in analysis are uncorrelated.
a. Varimax Method: minimizes the number
of variables that have high loadings on each factor. This method simplifies
the interpretation of the factors.
b. Quartimax Method: minimizes
the number of factors needed to explain
each variable. This method simplifies the interpretation of the observed
variables.
c. Equamax Method: combination of the varimax method, which simplifies
the factors, and the quartimax method, which simplifies the variables. The
number of variables that load highly on a factor and the number of factors
needed to explain a variable are minimized.
2- Oblique Rotation: SPSS has two oblique
rotation methods.
a. Direct oblimin Method
b. Promax Method: can be calculated more quickly than a
direct oblimin rotation, so it is useful for large datasets.
Decision to choose a
rotation method:
Tabachnick and Fiddell argue that “Perhaps the best way to
decide between orthogonal and oblique rotation is to request oblique rotation
[e.g., direct oblimin or promax from SPSS] with the desired number of factors and
look at the correlations among factor. If factor correlations are not driven by
the data, the solution remains nearly orthogonal. Look at the factor
correlation matrix for correlations around .32 and above. If correlations
exceed .32, then there is 10% (or more) overlap in variance among factors,
enough variance to warrant oblique rotation unless there are compelling reasons
for orthogonal rotation.”
Moreover, as Kim and Mueller put it, “Even the issue of
whether factors are correlated or not may not make much difference in the
exploratory stages of analysis. It even can be argued that employing a method
of orthogonal rotation (or maintaining the arbitrary imposition that the
factors remain orthogonal) may be preferred over oblique rotation, if for no
other reason than that the former is much simpler to understand and interpret.”
We can think of the goal of rotation and of choosing a
particular type of rotation as seeking something called simple structure.
Bryant and Yarnold define simple structure as:
A condition in which variables load at near 1 (in absolute
value) or at near 0 on an eigenvector (factor). Variables that load near 1 are
clearly important in the interpretation of the factor, and variables that load
near 0 are clearly unimportant. Simple structure thus simplifies the task of
interpreting the factors.
Thurstone’s 5 criteria
to choose a rotation method:
Thurstone first proposed and argued for five criteria that
needed to be met for simple structure to be achieved:
1-
Each variable should produce at least one zero
loading on some factor.
2-
Each
factor should have at least as many zero loadings as there are factors.
3-
Each pair of factors should have variables with
significant loadings on one and zero loadings on the other.
4-
Each pair of factors should have a large
proportion of zero loadings on both factors (if there are say four or more
factors total).
5-
Each pair of factors should have only a few
complex variables.
Zero loading- One
rule of thumb is that zero loadings includes any that fall between -.10 and
+.10.
Significant loading-
With a sample size of say 100 participants, loadings of .30 or higher can be considered
significant, or at least salient. With much larger samples, even smaller
loadings could be considered salient, but in language research, researchers
typically take note of loadings of .30 or higher.
Complex variables-
Variables with loadings of .30 or higher on more than one factor